
FPGA を使って遊びたいなぁということで高位合成を使って FPGA 上に回路実装をしていこうと思います.
他の回は以下から飛べます.
1. 使用したツールのバージョンとそれぞれの役割
- Vitis HLS
- バージョン: 2020.2
- 高位合成 (高級言語からハードウェア記述言語に変換する) のためのツール
- 今回は C++ を使って記述して,Verilog に変換します (Verilog を読んだりはしません)
- Vivado HLS
- バージョン: 2020.2
- Verilog で書かれた IP などから回路を作るのを支援し,bitstream を作ってくれるツール
- FPGA ボード
- 種類: Zynq UltraScale+ MPSoC ZCU104 評価キット
- Vivado で作られた bitstream を元に回路を作って実行してくれるボード
- PYNQ
- バージョン: PYNQ v2.6 (ZCU 104 用)
- 開発ボード向けのダウンロードページからダウンロード可能
- FPGA 上で動く Linux の一種で,回路にデータを送り込んだり,時間を計測したりするのに使用
- 先に PYNQ を準備したおきたい方は最終回の PYNQ を使って実機で動かす をご覧ください.
- バージョン: PYNQ v2.6 (ZCU 104 用)
- マイクロ SD カード
- PYNQ イメージを書き込むために使用
- 使用する PYNQ のバージョンにもよるが 16 GB 程度のものがあると良い
2. 大まかな流れ
まずは何から手をつければいいかわからない…と思うので,FPGA 上で回路を動かすための流れをまず簡単に説明します.
- C++ を使って Vitis HLS 用に実行したいコードを書く
- Vitis HLS を使って,シミュレーションをしてデバッグする
- Vitis HLS を使って,Verilog にコンパイルする
- コンパイルしてできた IP を使って,Vivado で回路を組む (これが難しい…)
- Vivado を使ってできた回路から bitstream を作成する (いわゆるジェネビ)
- 生成された bitstream を PYNQ にコピーする
- PYNQ で回路にデータを流して結果を得る
このような順番で回路を作って動かしていきたいと思います.
3. 今回行うこと
今回は 1. C++ を使って Vitis HLS 用に実行したいコードを書く の手順を解説していきたいと思います.
4. C++ を使って Vitis HLS 用に実行したいコードを書く
4.1. プロジェクト作成
まず,Vitis HLS を起動してプロジェクトを作成しましょう.
起動方法は GUI で Vitis HLS を探すか,terminal 等で $ vitis_hls & とすればいいと思います.
terminal でコマンドが認識されない場合はパスが通っていないと思うので,パスを確認してみてください.
うまくいけば下のようなページが表示されると思います.
次に,左上の File > New Project... を選ぶと,Project Configuration が出てくるので,以下のように適当な Project name (test) と Location (/path/to) を設定してください.
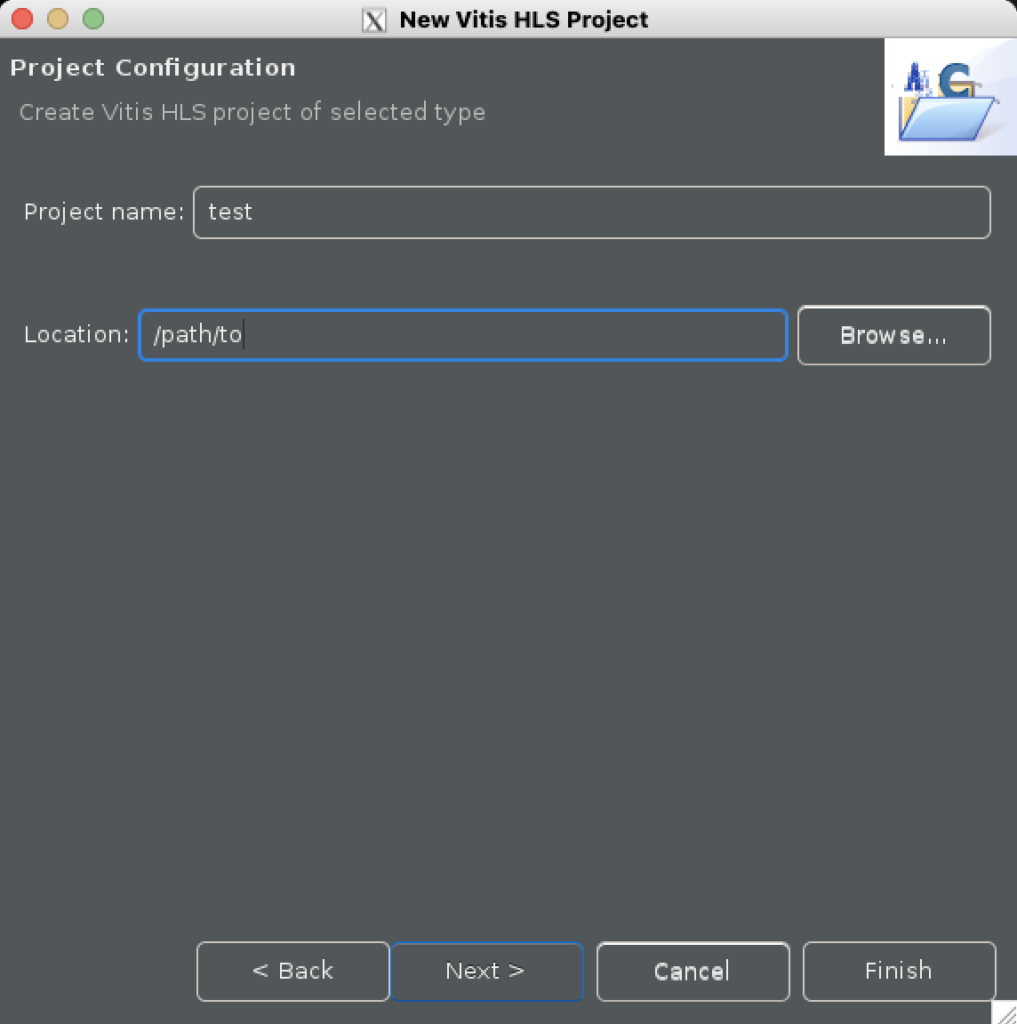
設定できたら,Next を押して進んでいきます.Add/Remove Design Files と Add/Remove Testbench Files は後で設定するので無視して飛ばしてください.
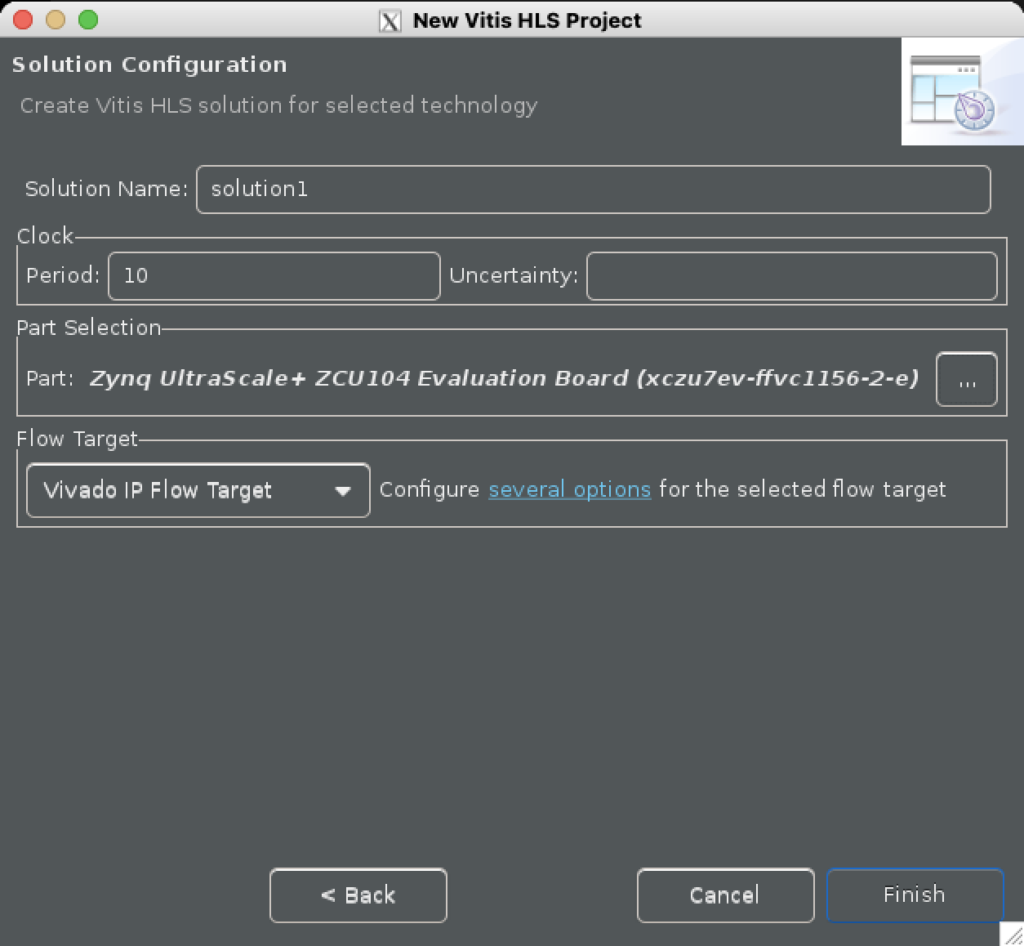
最後の Solution Configuration の部分では Part Selection を自分の持っているボード or パーツに変更してください.
その他の項目は基本的に変更しなくても大丈夫です.
筆者の場合は下のような画面になってますが,似たような画面になっていると思うので,右下の Finish を押してプロジェクト作成完了です.
以下のようなプロジェクトの画面が表示されたと思います.
すでに作っているプロジェクトを開くときは,右上の File > Open Project... 等から開くことができます.
4.2. コードの記述
無事プロジェクトが作成できたら,次はコードを書いていきます.
まず,プロジェクトを作ったフォルダの下にソースコードを入れる場所を作っておきましょう.
$ mkdir /path/to/test/srcXilinx のチュートリアル を使ってもいいのですが,今回は以下を参考にガウシアンフィルタを実装していきたいと思います.

まず,先程作ったフォルダ中に3つのソースファイル (gaussian.h, gaussian.cpp, gaussian_tb.cpp) を用意しておきます.
$ cd /path/to/test/src
$ touch {gaussian.h,gaussian.cpp,gaussian_tb.cpp}それぞれ,ヘッダファイル,メインとなるファイル,テストベンチのファイルとなります.
また,テスト用の画像として lena-gray.png をダウンロードしておきましょう.
$ cd /path/to/test/src
$ wget https://github.com/hashi0203/Vitis_HLS_Gaussian/raw/main/src/lena-gray.pngここからようやくコードを記述していきましょう.
コード自体は以下に上げているので適宜参照してください.

このプロジェクト全体を clone する場合は以下を実行してください.
$ git clone https://github.com/hashi0203/Vitis_HLS_Gaussian.gitまた,細かな書き方や最適化については Xilinx 公式の Vitis 高位合成ユーザガイド などを参照してください.
4.2.1 gaussian.h
まず gaussian.h で必要なヘッダファイルを include し,パラメータなどを定義しておきます.
ソースファイルでも,テストベンチでも使う情報をここに定義しておくと後で変更する時に楽です.
また,今回はデータ転送のために AXI Stream を使います
typedef ap_axis<32, 0, 0, 0> AP_AXIS;
typedef stream<AP_AXIS> AXI_STREAM;ちなみに ap_axis は以下のように定義されています.
template<int D>
struct ap_axis <D, 0, 0, 0>{
ap_int<D> data;
ap_uint<(D+7)/8> keep;
ap_uint<(D+7)/8> strb;
ap_uint<1> last;
};一方,AXI Stream を使わずに配列で書く方法もありますが,AXI Stream を使うと入力データが一つずつ入ってくる様子を意識しながらコードを書けるので,今回はこちらを採用します.
また,ガウシアンの係数については浮動小数点の計算をなくすためにあらかじめ求めた係数を shift ビットだけ左シフトしたもの (2^shift 倍したもの) を coeff に用意しておきます.
後は C++ と同じ要領で,定義していきます.
できたものをここに貼ると長くなるので,リンクにしておきます.
4.2.2 gaussian.cpp
メインとなるガウシアンフィルタの関数 void gaussian(AXI_STREAM &in_strm, AXI_STREAM &out_strm) を書いていきます.
普通に実装するのと同じように (テストベンチに書いてあるように) ガウシアンフィルタを書いても動く (はず) のですが,FPGA の特性を生かすためには回路に適した書き方を少ししてあげる必要があります.
参考にしているサイト の Version 2: efficient streaming using line buffers に書かれている図を使って説明します.
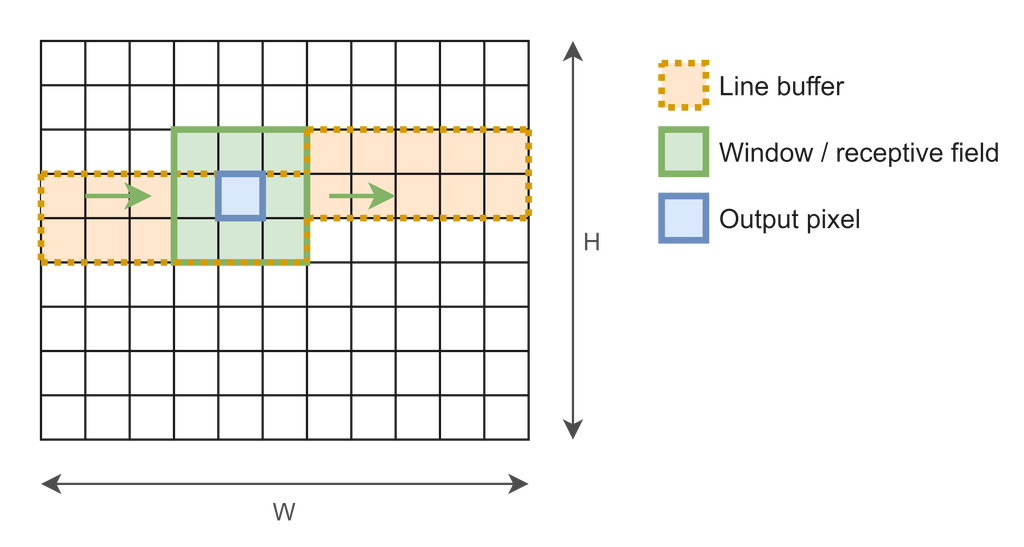
まず,今注目しているピクセルは青の Output pixel です.
このピクセルの計算結果を得るためにはそのピクセルを中心とした 3 x 3 の領域にあるピクセルが必要となります.
この領域が緑の Window / receptive field になります.
ここで,入力画像のピクセルは左上から右下に 1 つずつ順番に読み込まれるので,注目しているピクセルの計算結果を得るためには緑の領域の右下のピクセルが読み込まれるまで待たないといけません.
一方,緑の領域の左上のピクセルは右下のピクセルが読み込まれるまで,どこかに保存されていないといけません.
これを実現するのが,オレンジの Line buffer です.
ここで,必要なデータを保持するのにどれぐらいの領域が必要になるかを整理しておくと,
Window / receptive field: 9 ピクセルLine buffer: 2 行
となります.
この次のピクセルが読み込まれた時に,これがどのように変化するかを考えます.
まず,Output pixel は右に一つずれます.Window / receptive field も一つ右にずれるので,元から格納されていたデータを左に 1 シフトして,一番右の行には Line buffer と入力の値を格納します.
また,Line buffer については,右にずらしていってもいいのですが,少し非効率になってしまうので,新しく読み込まれた列だけを上に 1 シフトして,新しい入力値を一番下に格納します.
これで,必要なデータが格納された状態になっていることがわかると思います.
この操作を書いたものが gaussian.cpp となっています.
次に,pragma の使い方について,ここで使っているものだけ軽く解説しておきます.
まず,HLS INTERFACE ですが,これは入出力のインターフェースを決めているものなので,とりあえずそういうものだと思ってもらえれば大丈夫です.
次に,HLS PIPELINE についですが,これを指定することで,これより外のループがパイプライン化され,内側のループがインライン化されます.
インライン化されると,全てが同時に実行されるので,あまり大きすぎるループをインライン化してしまうとリソースを無駄遣いしてしまいます.
また,パイプライン化では今実行している i 回目のループが終わる前に,可能なら次の i+1 回目のループを開始します.
この開始間隔のことを II (Initiation Interval)と言いますが,これができるだけ 1 になるように次に説明するパーティションなどをうまく行うようにしてください.
最後にHLS ARRAY_PARTITION ですが,variable に指定された変数を dim で指定された次元方向に type (ここでは complete) で指定された分割タイプに応じて分割します.complete というのは完全に分割するということで,dim=0 は全ての次元に対してということなので,
int linebuf[d-1][width];
int window[d][d];
#pragma HLS ARRAY_PARTITION variable=linebuf complete dim=1
#pragma HLS ARRAY_PARTITION variable=window complete dim=0と設定することで, linebuf は linebuf[0], linebuf[1], ..., linebuf[d-1] と分けられていて, window は window[0][0], window[0][1], ..., window[d-1][d-1] と全てバラバラに分けられています.
なぜパーティションするかというと,FPGA に載っている BRAM (Block RAM) と呼ばれるメモリはポートが二つで,同時に二回しかアクセスができません.
つまり,同時に二回以上アクセスしようとすると,ストールが発生してアクセスが終わるまで待たないといけなくなってしまいます.
これでは II が大きくなって,実行時間が長くなってしまうので,各 BRAM へのアクセスが二回以内に収まるように分けるのがいいということになります.
逆に,バラバラに分けすぎてしまうと,リソースを無駄遣いすることになるので,過不足なく分けるように意識しましょう.
このような最適化を施したものが,以下のコードになります.
4.2.3 gaussian_tb.cpp
最後にテストベンチを実装すれば完成です.
こちらは OpenCV を使って画像を読み込んで,ソフトウェアでのガウシアンフィルタのナイーブな実装をし,これをハードウェア実装のシミュレーション結果と比較します.
結果が一致したかを出力してテストベンチは完成です.
5. まとめ
かなり長くなってしまいましたが,Vitis HLS でプロジェクトを作って,C++ でソースコードを書くところまで進むことができました 
次はコンパイルをして,実際にシミュレーションをしていきたいと思います.
