
Python の Selenium を使って面倒なフォーム入力やスクレイピングなどを自動で行ってくれるスクリプトを簡単に作っていきたいと思います.
1. 環境
- macOS Big Sur: 11.2.3
- Windows や Ubuntu でも同じようにできるはずですが,細部については異なる可能性があります.
- Google Chrome: 89.0.4389.114
- バージョンは Mac では右上の
⋮ > ヘルプ > Google Chrome についてで開くタブで確認可能です.
- バージョンは Mac では右上の
2. インストール
必要なパッケージなどをインストールしていきます.
まず, Selenium をインストールします.
$ pip install selenium次に,chromedriver_binary をインストールします.
こちらは Chrome のバージョンと同じ (または少し古いものでできるだけ新しいもの) を選ばないとエラーを吐かれてしまいます(厳しい…).A. 自分でバージョンを選んでインストールする方法 と,B. 自動でバージョンを合わせる方法 を紹介します.
A. 自分でバージョンを選んでインストールする方法
まず,chromedriver-binary から適切なバージョンを選んでください.
筆者の場合は Chrome のバージョンが 89.0.4389.114 だったので,それより少し小さい 89.0.4389.23.0 を選択します.
バージョンが決まれば,それを指定してインストールします.
$ pip install chromedriver_binary==89.0.4389.23.0この方法では残念ながら,Chrome のバージョンが上がった時に使えなくなってしまうことがあります.
B. 自動でバージョンを合わせる方法
こちらでは webdrive_manager を使って自動で Chrome のバージョンに合わせたドライバをインストールしてくれます.
(ちなみに,こちらでインストールするのは chromedriver_binary ではなく,chromedriver になります.chromedriver_binary は pip でインストールできて楽なので,一つ目の方法ではこちらを紹介しました.)
$ pip install webdriver_managerこれで,準備は完了です.
3. コードを書く
次はコードを書いていきましょう.
ここでは,Chrome の検索ページで Qiita と検索してスクレイピングをしてみましょう.
コードをブロックごとに実行して,開いたページを見ながらどこをクリックしたいかなど決めていくので,普通に python (hoge.py) で書くのではなく Jupyter Notebook (hoge.ipynb) などを使って書くことをおすすめします.
以下では chrome.ipynb に書いていきますが,#数字 で何番目のコードブロックかを表すことにします.
3.1. 必要なパッケージ等を import
from time import sleep
from selenium import webdriver
# A の方法でインストールした場合, chromedriver_binary を import して path を通します
import chromedriver_binary
# B の方法でインストールした場合,webdriver_manaeger を import します
from webdriver_manager.chrome import ChromeDriverManager3.2. ページを開く
まず,Chrome のページ “https://www.google.com/” を開きます.
# A の方法でインストールした場合
driver = webdriver.Chrome()
# B の方法でインストールした場合,ドライバを(必要なら)インストールして立ち上げます
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
page_url = 'https://www.google.com/'
driver.get(page_url)
sleep(1)最後の sleep はページの読み込みを待つために一応入れています.
これを実行すれば Chrome が立ち上がると思います.
3.3. ページの要素を取得して,検索する
次に Chrome の開発者ツールを開いてください.
画面内で右クリックして検証 (英語なら Inspect) を押したり, Cmd + Opt + I (Windows では Ctrl + Shift + I か F12) を入力することで開けます.
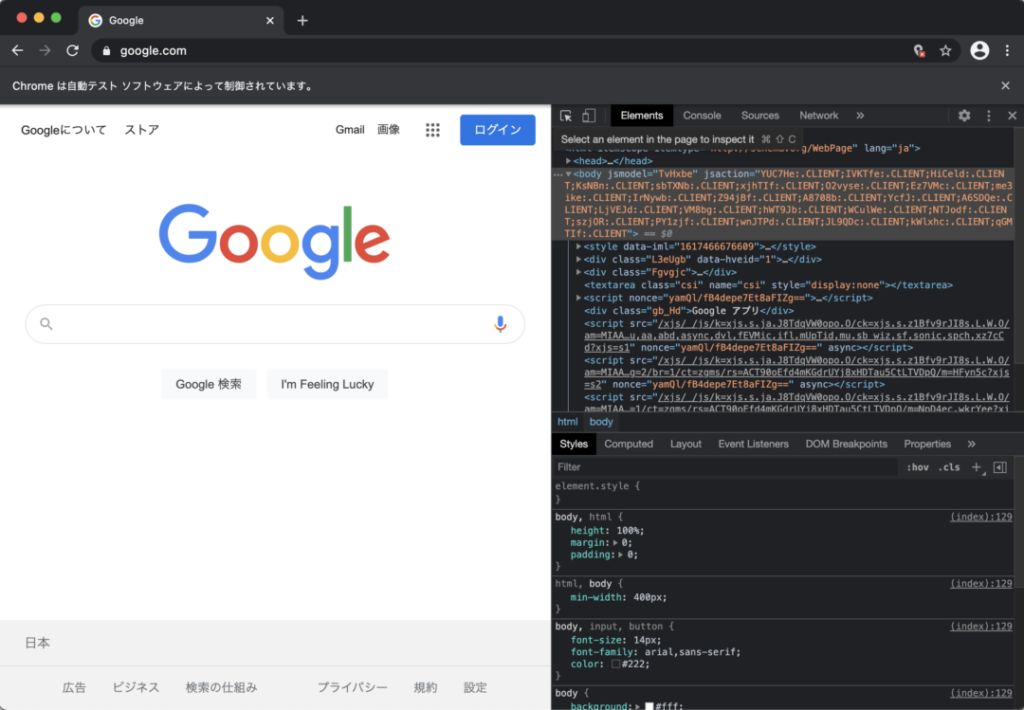
さらに,開いた開発者ツールの左上にある Select an element in the page to inspect it を押して青色にします.
もしくは,Cmd + Shift + C (Windows では Ctrl + Shift + C) でも可能です.
これで,ページ内の要素を選べるようになりました.
今回は検索をしたいので,検索ボックスを選んで,クリックします.
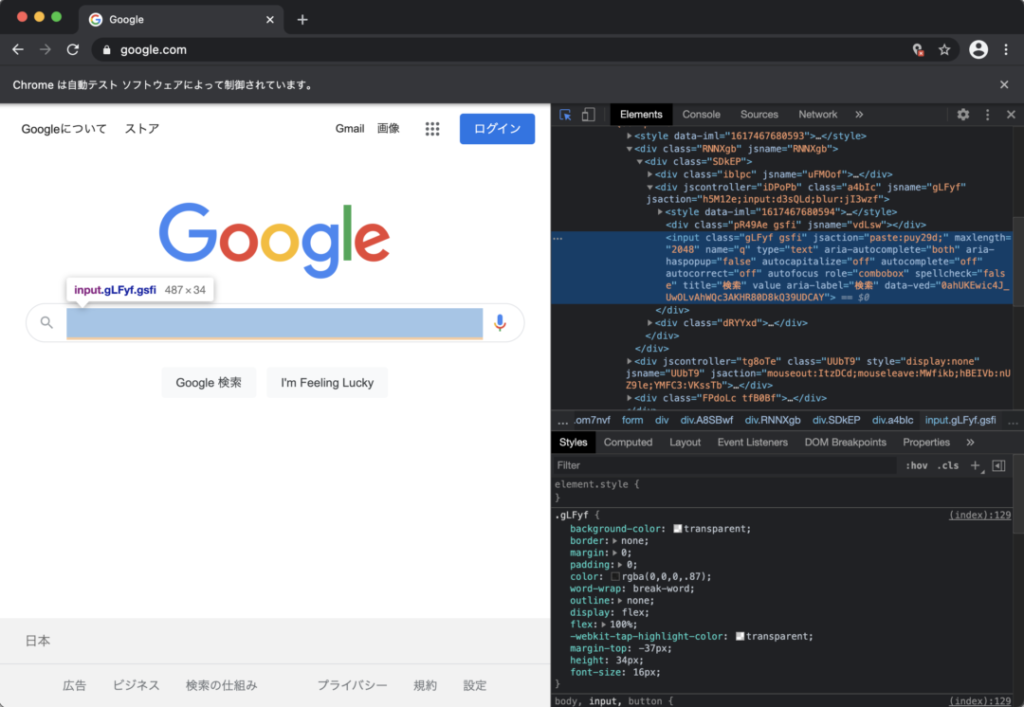
クリックすると,検索ボックスを表す HTML のソース部分にがハイライトされると思うので,その部分で右クリックをして,Copy > Copy XPath をしてください.
XPath というのは HTML のドキュメント内の要素や属性値などを指定するためのパスを表しています.
今回は,/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input になっていました.
次は,この場所に検索ワードを入れて,検索しましょう.
elem = driver.find_element_by_xpath('/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')
elem.clear()
elem.send_keys("Qiita")
elem.submit()
sleep(1)一行目で検索ボックスを取得して elem に格納しています.
二行目で中身を念のため空にした後,三行目で Qiita という文字列をボックスの中に入れて,四行目で submit することで,検索結果を表示します.
ちなみに検索ボックスを取得するためには XPath 以外にも id や class name を用いて,find_element_by_id, find_element_by_class_name とすることもできますが,XPath を使うのが一番確実だと思います.
3.4. 検索結果を集める
うまくいけば,検索結果が表示されていると思うので,後は情報を集めていきます.
検索結果の場所で再び開発者ツールを開いて確認してみると,各検索結果の文字列が h3 タグで囲まれていて,その一つ外側に a タグがあって,URL が格納されていることがわかります.

これらを取り出していきましょう.
今回はこの検索結果だけではなく,他の検索結果にもアクセスしたいので,少し工夫が必要です
先程と同様 XPath を使いますが,方針としては a タグの一つ内側にある h3 タグを列挙するという方針でいきましょう.
それで,列挙された h3 タグの一つ外側にある a タグから URL を取り,h3 タグからタイトルを取得しましょう.
for elem_h3 in driver.find_elements_by_xpath('//a/h3'):
elem_a = elem_h3.find_element_by_xpath('..')
print(elem_h3.text)
print('#', elem_a.get_attribute('href'))elem.text とすることでタグで囲まれた内側のテキストを,elem.get_attribute('hoge') とすることで,属性 hoge の値を取得することができます.
出力は以下のようになりました.
Qiita
# https://qiita.com/
Qiita (キータ) 公式 (@Qiita) · Twitter
# https://twitter.com/Qiita?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor
Qiita - Wikipedia - ウィキペディア
# https://ja.wikipedia.org/wiki/Qiita
Qiitaについて - Increments株式会社
# https://increments.co.jp/products/qiita
日本最大級のエンジニアコミュニティ「Qiita(キータ)」の ...
# https://www.a-tm.co.jp/news/service-19860/
Qiitaってなに?よく分からない人向けQiita基礎知識|ferret
# https://ferret-plus.com/1856この辺りは,以下のページも参考になると思います.

3.5. Chrome を閉じる
最後に Chrome を閉じて終了です.
driver.close()最後に閉じるのを忘れると閉じられないままどんどん開かれたブラウザが溜まっていってしまうことがあるので,しっかり閉じるようにしましょう.
3.6. コードをまとめる
これまで書いたコードが動くことがわかったら実行しやすいようにコードをまとめておきましょう.
Jupyter Notebook を使っている場合は Python に Export すればいいと思います.
また,不測のエラーにも対応して,Chrome を閉じられるように try 文で囲っておくのをおすすめします.
最終的には以下のようなコードになりました.(B の方法でインストールした場合を書きます.)
#1
from time import sleep
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
def main():
try:
#2
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
page_url = 'https://www.google.com/'
driver.get(page_url)
sleep(1)
#3
elem = driver.find_element_by_xpath('/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')
elem.clear()
elem.send_keys("Qiita")
elem.submit()
sleep(1)
#4
for elem_h3 in driver.find_elements_by_xpath('//a/h3'):
elem_a = elem_h3.find_element_by_xpath('..')
print(elem_h3.text)
print(elem_a.get_attribute('href'))
#5
driver.close()
print("Succeed")
except Exception:
# 失敗した場合も閉じておく
driver.close()
print("Fail")
if __name__ == "__main__":
main()4. まとめ
以上のようにして Selenium を使って簡単にスクレイピングができるようになったと思います.
フォームの入力も同じようにすれば自動化できるようになるので,ライフハックとして楽しんでください.
ラズパイを使ってこれを毎日同じ時間に実行するとかでさらに自動化したいという人は以下の記事をご覧ください!
